DeepSeek × 时间序列 :DeepSeek-TS,基于状态空间增强MLA与GRPO的时序预测新框架
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
这个的方法扩展了MLA,提出了MLA-Mamba。MLA-Mamba允许潜在特征通过具有非线性激活的状态空间模型动态演变,为模型提供自适应记忆,使其能够适应趋势变化。
同时通过GRPO引入了一种智能决策过程,将预测与基准进行比较来持续改进预测。这种动态调整有助于模型有效响应销售模式的突变。
本文将DeepSeek-TS框架与经典的ARMA模型和标准的基于GRU的网络进行了比较。结果表明,DeepSeek-TS能够建模复杂的产品间关系并适应非线性动态,从而产生更准确和稳健的预测。
在接下来的章节中,我们将详细介绍MLA的扩展(MLA-Mamba)和GRPO框架的技术细节,并展示它们的协同作用如何增强多产品时间序列预测。
在DeepSeek的MLA的核心思想是将key和value压缩到一个低维的潜在空间,从而减少模型在推理过程中需要存储的KV缓存大小。这个过程可以分解为以下几个关键步骤:
考虑一个维度为d的输入token向量h_t。在标准Transformer中,该向量通过学习矩阵被映射到查询(Q)、键(K)和值(V)空间。而在DeepSeek的MLA中,我们首先将h_t压缩成一个专门用于key和value的低维潜在向量。这可以通过以下公式来表示:
其中:
c_{KV,t}是压缩后的潜在向量。
W_{DKV}是下投影矩阵。
d_c是压缩维度,满足d_c≪d。
这种低秩近似类似于推荐系统中使用的矩阵分解技术,通过两个较小矩阵的乘积来近似一个大矩阵,从而捕获最显著的特征。W_{DKV}学习捕获计算注意力所需的h_t的最关键方面。
获得c_{KV,t}后,我们需要通过上投影,使用单独的矩阵重构用于注意力机制的key和value向量:
这里:
k_{C,t}是重构的key向量。
v_{C,t}是重构的value向量。
W*{UK}和W*{UV}是上投影矩阵,维度为R^{d_hn_h×d_c}(其中d_h是每个头的维度,n_h是头的数量)。
关键在于,在推理过程中,我们不需要为每个token缓存完整的key和value向量(这需要为每个token存储d_hn_h个元素),而只需要缓存压缩的潜在向量c_{KV,t},它只包含每个token的d_c个元素。当d_c远小于d_hn_h时,这种减少是非常显著的。
除了key和value之外,DeepSeek还可以对查询应用类似的低秩压缩,以减少训练过程中的激活内存。过程类似:
其中:
c_{Q,t}是压缩的查询向量。
W*{DQ}和W*{UQ}是查询的下投影和上投影矩阵。
d’c是查询压缩维度。
虽然压缩查询不会减少KV缓存,但它有助于减少训练过程中的整体激活内存。
假设你有一个Transformer层,其中每个token的原始key-value维度是1024(假设d_hn_h=1024)。使用MLA,如果你选择压缩维度d_c=128,那么你就将每个token缓存的数据量从1024个元素减少到128个元素,减少了8倍。在处理长序列或大规模部署模型时,这是非常显著的。
此外,在推理过程中,如果上投影矩阵W*{UK}和W*{UV}可以被吸收到其他权重矩阵中(如W_Q或W_O),那么你可能根本不需要显式计算或存储key和value,这样可以带来更大的效率提升。
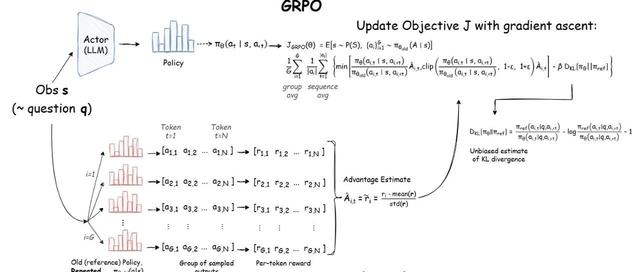
虽然MLA专注于高效的注意力机制,但DeepSeek还引入了一种新的优化方法,称为群组相对策略优化(GRPO),用于更新模型的决策策略。该方法基于强化学习原理,旨在平衡探索和利用,同时确保策略更新的稳定性。
在强化学习中,策略π(a∣s;θ)定义了在参数θ下,给定状态s时采取动作a的概率。目标是最大化预期累积奖励:
其中:
R_t是时间t的奖励。
γ∈[0,1]是决定未来奖励重要性的折扣因子。
GRPO引入了将新策略与先前(且固定)版本策略的输出群组进行对比评估的思想。关键在于,通过将新策略的输出与旧策略的输出进行比较,可以更稳健地衡量某些动作的优势。
令:
π_old为用于为同一查询q生成输出群组的策略。
π_new为当前可更新的策略。
比率:
衡量新策略相对于旧策略的偏差。
为了稳定训练,这个比率通常被限制在1−ϵ和1+ϵ之间,其中ϵ是一个小的超参数。这种限制确保策略在单次更新中不会发生过于剧烈的变化。
优势函数A_t量化了动作a_t相对于平均表现的优势程度:
其中V(s_t)是代表从状态s_t的预期奖励的基准值函数。在GRPO中,优势用于为更新加权,确保导致高于平均奖励的动作得到强化。
策略梯度更新由以下公式给出:
这个更新规则表明,应该在增加具有正优势动作概率的方向上调整θ,同时降低具有负优势动作的概率。
GRPO建立在之前的方法(如近端策略优化(PPO)和直接策略优化(DPO))的基础上,引入了一种新的机制,即将新策略的输出与旧的固定策略的输出群组进行比较。这种“群组相对”比较允许更稳定和可靠的更新。策略更新不仅考虑新策略的输出,还考虑它们相对于旧策略提供的一致基准的表现。
关键方程(概念):
其中:
clip(r_t,1−ϵ,1+ϵ)限制比率。
目标是最大化L(θ)。
这个方程确保如果新策略的偏差太大,更新会被限制,防止可能破坏训练的过度变化。
假设我们的RL代理负责为给定的查询选择最佳模型或模型组合。这个查询来自我们MLA过程生成的潜在表示z_t。假设旧策略πold为动作(如选择XGBoost、LightGBM、DNN或混合模型)分配概率分布,并对特定查询的“选择DNN”赋予0.25的概率。同时,新策略πnew可能为“选择DNN”分配0.35的概率。我们然后计算这些概率的比率。如果ϵ设为0.2,我们将比率r_t限制在区间[0.8,1.2]以确保学习稳定性。
如果ϵ设为0.2,那么我们将r_t限制在区间[0.8,1.2]。假设“选择DNN”的计算优势A_t为+0.5(表明在这种情况下选择DNN是有益的)。
策略梯度更新将使用限制后的比率:
这种受控更新有助于确保策略只会根据该动作相对于群组的表现情况逐渐向新的动作概率转移。
在本实验中,我们的目标是预测每种产品未来5天的平均销售量。我们使用AR(1)过程结合特定产品的噪声和偏移生成了一个包含600天数据的合成数据集。目标被定义为预测范围内的平均销售额。
数据经过标准化处理,然后按时间顺序分割(前80%用于训练,剩余20%用于验证),以确保进行时间外评估而不存在任何泄露。
比较了四种预测方法:
GRPO启发模型:包含一个GRU编码器和额外的策略分支。
扩展MLA(Mamba风格)的GRPO启发预测模型:使用具有ReLU激活的非线性状态空间方法更新潜在状态。
简单GRU模型:不含GRPO修改。
经典ARMA方法:对原始数据使用ARIMA(1,0,1)模型以滚动方式应用经典的ARMA方法。
GRPO启发模型,它集成了扩展MLA模块与GRU和额外的策略分支,展示了稳健的性能。在22个训练周期中,其MAPE稳步下降并最终稳定在21.6%左右。该模型的预测范围始终与目标范围保持良好一致,表明其自适应机制有效地捕获了潜在的销售模式。
相比之下,缺乏GRPO特定修改的简单GRU模型产生了略高的MAPE,平均约为22.3%。虽然简单GRU的预测也落在类似范围内,但GRPO模型观察到的边际改进表明,额外的策略损失和扩展的潜在更新有助于适度但有意义地减少预测误差。
具有扩展MLA(Mamba风格)机制的GRPO启发模型进一步改进了性能。其非线性状态空间更新,将ReLU激活应用于完整的状态更新,使MAPE降低到20.8-21.3%。这种改进表明使用更丰富的潜在表示在捕获时间序列动态方面具有优势。
最后,ARMA方法显示出显著更高的误差。每个产品的MAPE从约12.6%到超过43%不等,总体MAPE约为26.3%,ARMA在处理复杂的多维销售数据方面的效果不如深度学习方法。
总的来说,这些实验表明,深度学习模型,特别是那些通过GRPO和扩展MLA技术增强的模型,在预测多个时间序列的平均销售方面优于经典方法。
让我们总结DeepSeek的突破-MLA和GRPO-到一个自适应模型中。目标是构建一个系统,该系统不仅使用高效的低秩注意力来处理长序列,还利用强化学习来动态地智能选择或混合模型。
输入编码和潜在压缩:
每个输入tokenh_t首先由编码器处理。
编码器使用以下方式将h_t压缩到潜在表示:
将原始维度d减少到较小的潜在空间维度d_c。
重构Key和Value:
通过以下方式重构注意力所需的key和value:
这种重构确保保留了基本上下文的同时保持KV缓存较小。
查询压缩(可选):
注意力计算:
使用压缩的查询、键和值计算多头注意力。每个头应用常规的注意力公式,但减少的维度使得过程更加高效。
通过GRPO进行策略决策:
模型然后使用强化学习模块来选择最佳行动-无论是选择一个模型还是混合多个模型。RL策略π(a∣s;θ)接收状态s(包括来自MLA模块的潜在特征和额外的统计摘要)作为输入并输出一个行动。GRPO通过将新输出与早期固定策略的输出集进行比较来更新这个策略。计算优势并对更新进行裁剪以确保稳定性。
在前面的章节中,我们讨论了MLA和GRPO在DeepSeek中如何有效地协同工作,形成其核心技术。通过结合上面的技术,可以提出一个统一的框架,将MLA和GRPO结合用于多产品时间序列预测。使用包含日期、product1_sales、product2_sales、…、product5_sales列的DataFrame,我们的目标是预测每个产品未来10天的平均销售额。我们的方法将状态空间建模(使用”Mamba风格”方法)与潜在注意力相结合,并通过GRPO使用基于强化学习的策略优化来动态调整预测。
以下,我将概述数学基础、算法细节,并提供一个实际示例。
将销售数据表示为多变量时间序列:
{x_t},其中每个x_t表示时间t时p个产品(这里p=5)的销售量。
目标是预测每个产品未来10天的平均销售额。
这里的挑战在于时间序列可能存在内部相关性和滞后效应。例如,产品1在第t天的销售量可能不仅取决于其自身过去的销售量,还取决于产品2或产品3前几天的销售量。
为了捕获时间序列预测中固有的时间动态,我建议用非线性激活增强的状态空间更新来扩展潜在压缩步骤。在这个框架中,我假设压缩的潜在向量根据以下方式随时间演变:
其中:
M∈R^{d_c×d_c}是建模潜在状态动态的转移矩阵。
η(x_t)是一个函数,将当前输入x_t(如时间t的销售数据)映射到潜在空间中的校正项。
ReLU激活应用于整个更新,引入非线性并确保更新后的潜在状态为非负。
可以对查询压缩应用类似的更新:
其中M’∈R^{d_c’×d_c’}的定义类似。
**解释:**这个状态空间更新”记住”过去的潜在状态c{KV,t}并使用新信息x_t对其进行调整。通过对整个和应用ReLU激活:
,模型捕获历史状态与新输入之间的复杂非线性交互。非线性有助于建模复杂的时间模式,同时确保潜在表示保持非负。这种方法类似于RNN或LSTM更新其隐藏状态的方式。
在获得动态潜在状态c*{KV,t}和c*{Q,t}后,我将它们投影到多头注意力的键、值和查询中。
假设我将潜在空间分成h个头。对于头i:
其中W*{Q,i}、W*{K,i}、W_{V,i}和d_h为每个头的维度。
每个头的注意力计算为:
然后将所有头的输出连接起来并用输出矩阵W_O投影:
这种多头机制使模型能够捕获销售数据中时间关系的不同方面。例如,一个头可能学习趋势分量,另一个可能关注季节性,等等。
在这个框架中,我们首先定义在给定长度为T的输入窗口和H天预测范围内的预测问题。对于每个产品时间序列,目标y被计算为未来H天原始销售量的平均值,即
其中x_t表示第t天的销售量。
GRPO模型使用两层GRU从标准化输入序列X∈R{T×D}(D为产品数量)中提取时间特征。令最后一个时间步的隐藏状态为h_T∈RH_d。这个h_T然后通过两个单独的线性投影映射:
预测分支使用权重矩阵W_f计算预测:
其中y是每个产品预测的平均销售量向量。
策略分支通过另一个线性映射W_p计算一个标量值p(策略值):
GRPO启发损失的核心思想是基于一个”优势”信号来调整预测,该信号衡量预测误差相对于常数基准b(这里选择b=0.5)的表现。
具体而言,优势被定义为:
其中平均值在产品维度上取均值。策略值与基准之间的比率r计算为:
为了确保训练期间的稳定性并避免大的策略更新,使用了裁剪机制。令:
其中ϵ是一个小值(例如0.1)。GRPO启发的策略损失则被公式化为:
如果新策略(即预测)没有相对于基准充分改进,该损失会对模型进行惩罚。总体损失函数是预测损失和策略损失的组合:
其中,
λ是控制策略损失权重的超参数。
这种方法被嵌入到时间外验证方案中:时间序列数据按时间顺序分割,确保只使用过去数据进行训练,未来数据用于验证-从而避免数据泄露。在验证期间,使用存储的均值和标准差将归一化预测y转换回原始尺度,并计算平均绝对百分比误差(MAPE):
其中ϵ是一个小常数,用于避免除以零。
在这里,用于多时间序列预测的GRPO方法使用GRU编码器提取时间依赖特征,并产生预测和策略值。预测使用组合的MSE/MAE损失进行评估,而策略分支使用裁剪优势机制提供额外的梯度信号,最终导致对预测范围内的平均销售额进行更稳健的预测。
本文介绍的DeepSeek-TS方法利用GRPO结合使用Mamba风格状态空间更新的扩展MLA模块。实验表明,这个GRPO启发模型可以实现更好的性能-更低的MAPE-比简单的GRU模型和经典的ARMA方法。由策略分支和状态更新中的非线性激活驱动的增强潜在表示似乎能更有效地捕获销售数据的复杂动态。
GRPO和扩展MLA框架在应用于其他领域方面具有巨大潜力。例如,这种方法可以适用于金融时间序列预测,在这种情况下捕获市场趋势的细微变化至关重要。它也可能对医疗保健诊断有益,在那里从多个时间相关信号预测病人结果可以导致更早的干预。
未来的工作可以集中在通过实验不同的基准值或裁剪阈值来进一步改进GRPO机制,以及探索扩展的MLA模块如何与其他深度学习架构集成。此外,整合元学习技术可能使模型能够在不同领域之间更好地泛化。总的来说,这项研究表明,将强化学习与先进的注意力机制相结合是构建更智能、更具适应性的预测系统的一个有前途的方向。
代码:https ://github.com/datalev001/DeepSeek-TS
最后说明,我看了一下作者的github代码,用了其他的序列数据测试,得到的结果和这篇文章有一些出入,但是作者的思路我觉得可以借鉴。如果你自己测试的话,欢迎留言回复测试结果
长按👇关注-机器学习研习院-设为星标,干货速递