不一样的推测解码!大LLM带小LLM,出奇的好,还有意外收获
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
小模型,为什么需要大模型“带飞”?
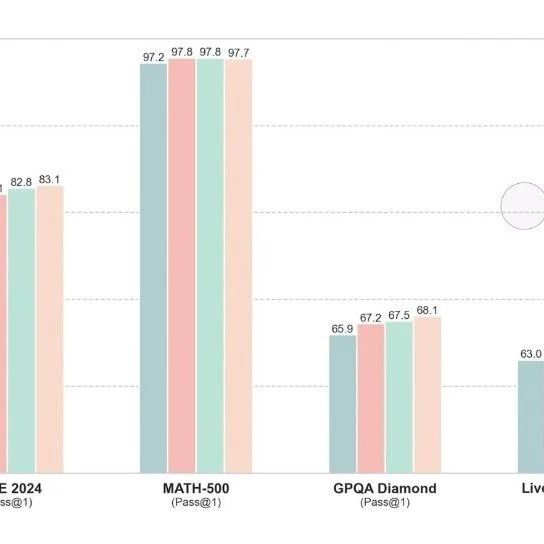
小模型(如1.5B参数)虽然轻量、省电,但遇到复杂数学题或逻辑推理时容易“卡壳”——要么答案错误,要么啰嗦半天还绕不出去。传统解决方案需要大量数据和算力重新训练模型,成本极高。显示,小模型在数学题上的准确率仅为83.2%,而输出长度却是大模型的近两倍!
就像小学生做奥数题,自己琢磨容易走偏,但如果有老师偶尔点拨关键步骤,效果立竿见影。
研究者发现,模型在推理时会频繁出现“\n\n”符号(类似段落分隔符),紧接着常伴随“等等,这里有问题?”(如“wait”“alternatively”)等反思性词汇。显示,超过80%的反思词汇紧跟在“\n\n”之后,说明这是模型“自我怀疑”的信号点。
就像人解题时写一段停一下,画个分隔线,然后嘀咕“刚才那步对吗?”这时候最需要外部指导。
SpeculativeThinking的核心是:小模型主攻常规步骤,大模型专治“选择困难症”。具体通过三种机制实现:
反思接管:小模型遇到“\n\n+反思词”时,大模型接手生成下一步;
验证接管:小模型说“我再检查一下”,大模型直接代劳;
防死循环:小模型反复纠结超3次,大模型强行介入破局。
展示了这一动态协作流程。
仅需替换约20%的关键片段,就能大幅提升性能,像给汽车换了个涡轮增压器。
实验结果堪称“逆天改命”:
1.5B小模型在MATH500数据集上准确率从83.2%→89.4%(+6.2%),输出长度减少15.7%;
连非推理专用模型(如7B-Instruct)也能蹭到红利,准确率提升7.8%。
显示,大模型介入后,小模型的“废话量”明显减少,尤其错误答案的冗长度大幅降低。
更神奇的是,这套方法对非推理专用模型也有效!例如,Qwen-7B-Instruct本身不擅长数学,但通过大模型指导,其MATH500准确率从74%→81.8%。显示,这种提升虽伴随输出变长,但性价比极高。就像被学霸附体,虽然解题步骤变多,但正确率飙升!
传统SpeculativeDecoding只加速生成(如小模型写草稿,大模型改错字),而SpeculativeThinking直接干预推理逻辑。对比显示,前者可能因“草稿太差”频繁返工,后者则精准切入关键卡点,效率更高。
依赖大模型能力:如果“导师”不够强,效果打折扣;
同家族限制:目前仅支持同系列模型协作(如Qwen家族);
提示词敏感:指令如“请逐步推理”对效果影响显著。
这项技术让“小模型+大模型”组合成为可能:日常任务用小模型省成本,关键时刻调用大模型保质量。未来或应用于教育助手、代码调试等场景,实现低成本高智能的普惠AI。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦