LLM Agent也能通过RL学会「思考」和「自我进化」吗?
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
Agent也需要『思考』和「自我进化」?
比如你教一个小孩玩游戏——不是一次教完所有步骤,而是让他自己摸索,通过多次尝试和失败来学习。这篇论文的核心,就是让AI像人类一样,在多轮互动中自我进化。
传统模型训练像是「开卷考试」:给一个问题,直接生成答案。但现实中的任务(比如玩游戏、机器人控制)需要AI像打游戏一样,连续决策,并根据环境反馈调整策略。这就像让其从「做题家」变成「实战派」。
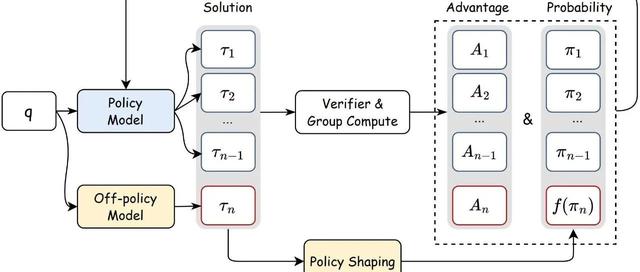
论文提出的RAGEN系统和StarPO框架,正是为了解决这一挑战,让Agent在复杂、随机的多轮任务中稳定学习。
StarPO的核心思想是「整局优化」。传统方法只看单次动作的对错(比如一次数学题的答案),而StarPO要求Agent把整个任务流程(比如游戏的一整局)当作学习单元。
举个🌰:玩「推箱子」时,AI不仅要考虑下一步怎么推,还要规划整个路径,避免中途卡死。StarPO通过轨迹级奖励(比如通关后的高分)来优化全局策略,而不是单步得分。
最大化整局游戏的总奖励,而不是某一步的得分:
论文发现,Agent在多轮训练中会掉进「回音陷阱」(EchoTrap):初期表现多样,后期却重复固定话术,比如总说「选龙臂,因为龙代表力量」,但实际是瞎蒙的。这种「复读机行为」导致奖励方差骤降、探索能力消失,最终性能崩溃。就像学生考试时死记硬背模板,遇到新题直接挂科。论文用梯度爆炸、奖励标准差等指标提前预警这一问题(见下图),并提出了改进方案StarPO-S。
只保留高不确定性的训练样本(比如AI在不同尝试中得分波动大的任务),过滤掉太简单或太难的内容。这类似于老师重点讲解学生易错的题目。
移除限制AI探索的KL散度惩罚,让AI更自由地尝试新策略。
对高分表现放宽奖励上限,对低分表现严格惩罚,加速高质量策略的学习。
论文发现,即使强制Agent输出「思考过程」(比如用标签),如果奖励只看最终结果,会逐渐「偷懒」,变成「直接蒙答案」。
🌰在「老虎机」任务中,能通过符号联想(比如「龙」代表高风险高收益)泛化到新场景;但在「推箱子」等复杂任务中,Agent的「思考」只是应付格式,实际在瞎猜。
关键结论:必须设计细粒度奖励,比如对推理逻辑单独打分,否则Agent的「思考」只是表面功夫。
论文在三个游戏中测试StarPO-S:
老虎机:AI学会高风险高收益策略;
推箱子:多步规划能力提升;
冰湖(滑溜溜的迷宫):PPO算法因环境随机性翻车,但GRPO(无价值函数)更稳定。
这套方法可扩展到机器人控制、科学发现等领域。但当前局限也很明显:
依赖清晰奖励(比如游戏得分),现实任务中难以定义;
长上下文训练效率低(比如处理复杂任务时显存爆炸)。
论文团队已开源代码和环境,期待更多开发者参与探索!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦