TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
机器之心报道
编辑:蛋酱、+0
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。OpenAI的o系列、Anthropic的Claude和DeepSeek-R1等模型的惊艳表现背后,测试时缩放(TTS)技术功不可没。
测试时缩放(TTS,Test-TimeScaling)是一种提升大语言模型推理能力的新兴策略,通过在测试阶段优化推理过程(如多数投票、蒙特卡洛树搜索等)提升大型语言模型(LLMs)的性能,而无需修改模型参数。
研究表明,TTS在计算效率上优于预训练阶段扩大模型规模,能以更低资源成本实现更好表现。然而,TTS依赖预训练知识,在面对未标注新数据或输入分布变化时,泛化能力受限。如OpenAIo3在某基准任务上达到75.7%的成功率,对更复杂的新任务却仅能解决4%的问题。
为克服TTS的局限,测试时训练(TTT,Test-TimeTraining)一度受到广泛关注。TTT通过在测试阶段利用RL等技术动态更新模型参数,使模型适应新数据或任务,弥补了TTS在泛化能力上的不足。但TTT同样面临自身的挑战:测试阶段缺乏奖励函数或验证信号,而人工标注数据的高成本使得无监督环境下的RL应用受限。
在最新的一篇论文中,清华大学和上海人工智能实验室提出了一种新方法——测试时强化学习(Test-TimeReinforcementLearning,TTRL),该方法能够在无标注数据上对LLM进行强化学习训练。
论文标题:TTRL:Test-TimeReinforcementLearning
论文地址:https ://arxiv.org/abs/2504.16084
GitHub:https ://github.com/PRIME-RL/TTRL
HuggingFace:https ://huggingface.co/papers/2504.16084
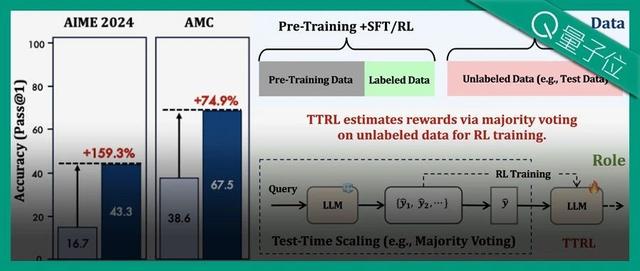
TTRL通过利用预训练模型中的先验知识,使LLM具备自我演化的能力。实验证明,TTRL在多种任务和模型上都能持续提升性能:在仅使用未标注测试数据的情况下,TTRL将Qwen-2.5-Math-7B在AIME2024任务中的pass@1指标提升了约159%。
值得注意的是,虽然TTRL仅依靠Maj@N指标进行监督,但其表现不仅能持续超越初始模型的性能上限,更能接近于那些直接在有标注测试数据上进行监督训练的模型性能。实验结果验证了TTRL在多种任务中的广泛有效性,充分展示了该方法在更广阔领域中的应用潜力。
方法
图2展示了研究者提出的TTRL方法如何应对此类挑战。给定状态表示为输入提示x(promptx),模型依据参数化策略π_θ(y|x)生成输出y。为了在无真实标签的条件下构造奖励信号,研究者通过重复采样的方法,从模型中生成多个候选输出{y₁,y₂,…,y_N}。接着,使用多数投票(majorityvoting)或其他聚合方法从这些候选中推导出共识输出y,作为近似的最优动作(optimalaction)的替代。
环境反馈的奖励r(y,y)则根据当前动作y与共识输出y*之间的一致性进行设定。模型的RL目标是最大化期望奖励:
通过梯度上升(gradientascent)更新参数θ:
该方法能够在推理阶段实现模型的动态适应,无需标注数据即可提升模型应对分布变化输入时的性能。
多数投票奖励函数(MajorityVotingRewardFunction)
多数投票奖励机制的核心在于:首先借助多数投票策略估算一个伪标签(pseudo-label),再基于该估计标签计算规则驱动的奖励(rule-basedrewards),并作为最终用于RL训练的奖励信号。
在具体操作上,给定一个输入问题x,研究者对其输入到大型语言模型中,并生成一组输出结果。随后,答案抽取器(answerextractor)对这些输出进行处理,提取对应的预测答案,记为P={ŷᵢ}ⁿ_{i=1}。接着,研究者在集合P上应用第4节定义的多数投票策略函数s(y,x),选出出现频次最高的预测y,作为估计标签。
随后,该多数投票结果y被用作标签估计,用于计算基于规则的奖励信号:
实验
TTRL在大多数任务和模型上都表现出色。尽管TTRL完全依赖于使用无标注测试数据的自我进化,但其性能却可媲美基于大规模标注数据集训练的现有RL模型。如表1所示,在AIME2024上,TTRL实现了159.3%的大幅提升,超过了所有在大规模数据集上训练的模型。此外,当应用于Qwen2.5-Math-7B时,TTRL在三个基准测试中平均提高了84.1%。
TTRL自然扩展。另一个值得注意的现象是,随着模型大小的增加(从1.5B到7B),其在AIME2024和AMC上的性能提升也在增加,这凸显了TTRL的自然扩展行为:更大的模型可以在自我改进过程中产生更准确的多数投票奖励,从而更有效地学习新数据。不过,LLaMA-3.1-8B-Instruct和Qwen2.5-Math-1.5B可能由于容量有限,未能通过TTRL在AIME2024上取得有意义的进展。相比之下,Qwen2.5-Math-7B的模型容量更大,知识更充分,因此可以从自我改进中获益,从而取得明显的性能提升(第4.3节会详细讨论这一点)。
TTRL在目标任务之外也有很好的通用性。研究者以Qwen2.5-Math-7B为骨干,在每个基准上执行了TTRL,并在其他基准上进行了进一步评估。图3展示了结果。尽管这种设置具有分布外的性质,但TTRL在所有基准上都取得了实质性的改进。这表明TTRL并没有依赖过拟合(过拟合会导致在其他任务上的取舍),而是在自我改进过程中获得了可推广的收益。
TTRL与不同的RL算法兼容。图4展示了结果。研究者在MATH-500上使用PPO应用TTRL,以评估其与不同强化学习算法的兼容性。PPO和GRPO的性能轨迹非常接近。与GRPO相比,PPO能产生更稳定的结果,同时实现相似的整体性能。
讨论
Q1:TTRL的性能能有多好?
研究者使用了两个上限来分析TTRL的潜在性能。第一个上限是Maj@N,用于计算TTRL训练过程中的奖励。第二个上限是在基准数据集上的直接训练,它假定可以访问ground-truth标签,因此会向策略模型泄露标签信息。
关键发现如下:
1.TTRL不仅超越了其训练信号和初始模型的直观上界Maj@N,还接近了用标注测试数据训练的直接RL的性能。这一进步可能要归功于TTRL使用RL进行测试时间训练:通过将基于投票的伪标签转换为奖励,它提高了有效监督的质量,同时使学习摆脱了Maj@N的限制。
2.TTRL的经验上限是在测试数据上进行训练(即在测试数据上进行训练),这凸显了它与标准训练评估协议相比在功效上的潜在优势。
3.对于具有挑战性的任务,TTRL只需使用1.5B模型即可达到经验上限。这表明,现在LLM可以通过TTRL有效地自我进化,从而在大规模数据集上实现无限制的终身学习。
TTRL受Maj@N监督,却超越了Maj@N。图6展示了TTRL在Qwen2.5-Math-7B上的测试结果。可以看出,在所有基准测试中,TTRLAvg@64均优于Qwen2.5-Math-7BMaj@64,大大超出预期。此外,在应用多数表决时,TTRL的性能也有大幅提升。
TTRL的「性能增益法」基准训练,图7展示了结果。令人惊讶的是,TTRL的性能曲线非常接近RL(泄漏)的性能曲线。
Q2:TTRL为何有效?
这一节主要分析了TTRL在无监督条件下实现稳定有效的RL的因素,包括两个关键方面:标签估计和奖励计算。
标签估计。TTRL与标准RL算法的一个直接区别是,TTRL涉及标签估计,而标签估计会带来奖励误差。研究者认为,尽管存在这些误差,TTRL仍能正常工作,原因有以下两点:
(i)现有研究表明,RL可以容忍一定程度的奖励不准确性。此外,与通常依赖于记忆训练数据的监督微调(SFT)相比,RL的泛化效果往往更好。在RL中,奖励通常是模糊的,主要是作为探索的方向信号,这导致了RL对奖励噪声的鲁棒性。
(ii)之前的研究还从优化的角度研究了什么是好的奖励模型,发现更准确的奖励模型不一定是更好的教师。因此,由政策模型本身估计的奖励信号可能会为学习提供更合适的指导。
奖励计算。当模型能够通过多数投票估算出准确的标签时,随后估算出的奖励一般都是可靠的。然而,一个自然而然的问题出现了:为什么在AIME2024等具有挑战性的基准上,即使模型无法估算出准确的标签,TTRL仍然有效?
研究者表示,最根本的原因在于RL中奖励的定义。基于规则的奖励是根据预测答案是否与「标签」匹配来分配的。因此,即使估计的标签不是ground-truth,只要它与错误预测的答案不同,系统仍可分配正确的「负」奖励。
为了提供更详细的案例研究,研究者在Qwen2.5-Math-7B上检验了TTRL在AIME2024上的性能。图8显示了三个指标的变化曲线。
研究者发现了TTRL在AIME2024上依然有效的两个主要原因:
首先,奖励比标签更密集,即使估计的标签不准确,也有更多机会恢复有用的学习信号。
其次,当模型能力较弱时,TTRL给出的奖励可能更准确。
Q3:TTRL何时失效?
在算法层面,TTRL与现有的RL算法并无本质区别,因此继承了它们的一些特点,如对数据难度的敏感性、对先验的强烈依赖性以及在某些条件下崩溃的风险。
在实现层面上,这些问题因TTRL的限制而进一步扩大,TTRL通过多数投票来估计标签,并且只在稀疏和以前未见过的测试数据上运行,在某些情况下可能会导致失败。
在初步实验中,研究者发现了两个潜在问题:
缺乏对目标任务的先验知识。如表2所示,研究者发现,随着问题难度的增加,性能提高率和长度缩减率都呈下降趋势。这表明主干系统的可用先验知识不足以支持对更具挑战性问题的学习。
不恰当的RL超参数。图10比较了在AIME2024上的几次失败尝试。
更多研究细节,可参考原论文。
©THEEND
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com