仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
为什么需要控制生成内容?
如今的大语言模型(如GPT、Gemma)虽然能写诗聊天,但有个致命问题——它们像“走一步看一步”的短视者。生成内容时,模型只根据当前已生成的文本预测下一个词,无法全局考虑“整段话是否合规”。比如写一段去毒化内容,模型可能前半段正常,后半段突然“翻车”。
传统解决方案有两种:
训练法:为每个新属性重新训练模型(费钱费时,还可能让模型变笨)。
采样法:暴力穷举未来可能(速度慢,效果不稳定)。
因此,本文提出新方法TRACE,巧妙解决上述问题。
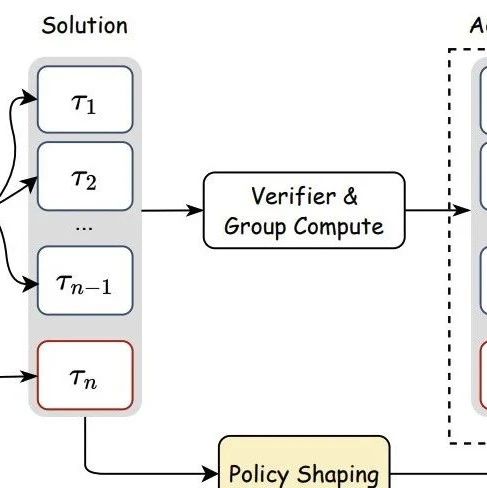
TRACE的核心创新是用概率模型模拟未来,像给装了个“预判雷达”。它包含两大组件:
HMM导航地图:将复杂的大语言模型蒸馏成一个简化的隐马尔可夫模型,能快速预测未来可能路径。
智能过滤器:针对每个属性(如“非毒性”)训练轻量级分类器,判断整段文本是否符合要求。
关键公式:未来属性概率(EAP)
预测未来合规概率
简单理解:通过HMM预测所有可能的后续路径,再用分类器打分,最终算出一个“综合合规概率”。
在“毒性内容生成”测试中,TRACE仅增加10%的生成时间,毒性概率(>0.5)从基准模型25.4%降到2.6%,媲美需要大量训练的强化学习方法(如DPO)。更厉害的是,它保持了原文的流畅性和多样性,不会像某些方法那样生成机械重复的内容。
用TRACE为GPT-2大模型适配76个虚拟角色(如林肯、雷神),每个角色只需3秒训练+少量示例。相比之下,传统方法需要重新训练整个模型,耗时数小时。
通过简单乘法组合不同属性的概率,TRACE能生成同时满足“政治相关”和“非毒性”的内容。这种灵活组合能力在传统方法中几乎无法实现。
零成本适配:无需修改大模型,加个“外挂”就能控制生成。
速度逆天:适配新属性只需训练一个小分类器(最快3秒)。
可控性强:通过调节参数(如图3中的解码系数),用户可自由平衡“流畅度”和“合规性”。
从论文结果看,TRACE可能在以下场景大放异彩:
内容安全:自动过滤社交媒体有害言论
个性化助手:快速定制“打工人版”“萌妹版”AI
专业写作:生成同时满足“学术严谨+通俗易懂”的文章(我要这个!)
未来若能进一步提升HMM的预测精度,TRACE或许能成为AI时代的“生成内容交警”。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦