PD分离也有问题?semi-PD降低两倍延时,增加一半吞吐!
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
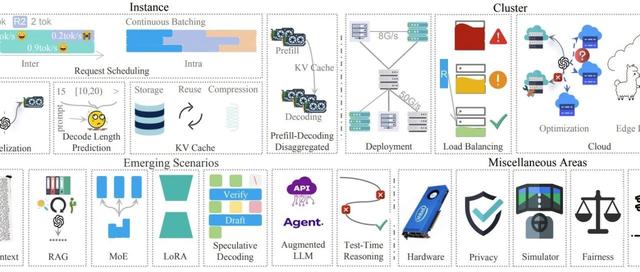
大模型服务的效率困局大型语言模型(如ChatGPT、Llama)的服务过程分为两个阶段:预填充(prefill)和解码(decode)。前者负责理解用户输入并生成第一个词,后者像“打字机”一样逐个输出后续内容。
现有系统分为两大阵营:
统一派:两个阶段共用同一块GPU,但会互相“抢资源”,导致延迟不稳定。
分家派:两个阶段用不同GPU,虽然不抢资源了,但存储效率低(比如模型参数要存两份),调整资源分配时像“搬家”一样麻烦。论文指出,分家派的最大问题是存储浪费:预填充阶段生成的中间数据(KV缓存)大部分存在解码GPU上,预填充GPU的存储空间长期闲置,就像“停车场白天停满车,晚上却空着”。
semi-PD提出“分家计算,统一存储”的架构:
计算分家:预填充和解码像餐厅的“厨房区”和“用餐区”,各自有专用灶台(SM计算单元),互不干扰。
存储统一:所有数据存在同一个“冰箱”(GPU内存),避免重复存储和搬运。
这套设计的精髓在于动态调整:根据实时流量,厨房和用餐区可以快速“扩缩容”。比如用餐高峰时,临时把几个灶台改成用餐区座位,且调整过程几乎无感(类似餐厅翻台)。
传统分家系统调整资源需要重启GPU进程,耗时几分钟。semi-PD通过“常驻进程+指针共享”,让调整像“换灯泡”一样快——旧灯一关,新灯秒亮,且冰箱里的食材(存储数据)不用搬动。
预填充和解码可能同时申请存储空间,导致“你刚查完余额,我就把钱转走”的冲突。semi-PD引入原子操作锁,确保每次分配像银行柜台一样“一次只办一笔业务”,避免数据混乱。
论文在Llama、DeepSeek等模型上测试发现:
延迟降低:平均请求耗时减少1.27-2.58倍。
吞吐量提升:在相同延迟约束下,semi-PD能多处理55%-72%的请求。
集群表现:混合部署semi-PD节点后,长文本等复杂场景的延迟波动更小。
semi-PD的核心理念——解耦计算与存储——为未来优化指明方向:
硬件设计:支持更细粒度的资源划分
云服务:按需分配资源,降低成本
边缘计算:轻量级部署成为可能
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦