仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
当前大模型依赖海量人类标注数据,但标注成本高、扩展难。论文直指核心问题:能否让模型像人类一样自我纠错、自主进化?尤其在数学推理等复杂领域,人类也可能不会解题,模型必须学会“自学成才”。
论文:CanLargeReasoningModelsSelf-Train?链接:https ://arxiv. org/pdf/2505. 21444v1
研究团队提出自我奖励训练(SRT):
步骤1:让模型对同一题目生成32个答案
步骤2:用“多数投票”选出高频答案作为“伪标准答案”
步骤3:用投票结果作为奖励信号训练模型
本质上,模型用自己的共识代替人类标注,形成自进化闭环。
在MATH、AIME等数学数据集上:
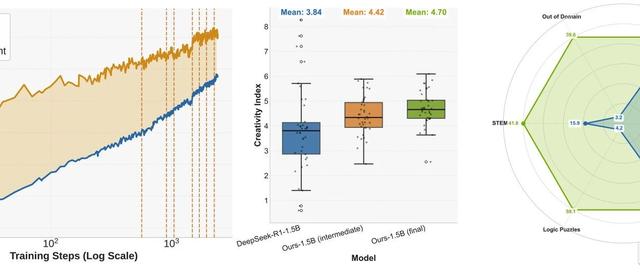
SRT早期性能≈人工标注的强化学习
峰值性能提升达100%(相比原始模型)
发现:首次证明大模型可在零人工标注下自我进化!
但在高难度数据集DAPO上出现诡异现象:
训练400步后性能突然崩溃
模型开始对所有问题输出“\boxed{1}”论文发现:统一错误答案能骗过投票机制!
公式揭示本质:SRT奖励“一致性”而非正确性奖励答案投票共识其他情况
用1%验证数据监控性能,在崩溃前保存模型
用初始模型生成固定标签,避免动态投票被污染
只训练“简单题目”(前1/3易题),性能反超全量训练!
最后,作者开源所有代码/数据集,大家快来试试:https ://github. com/tajwarfahim/srt
备注:昵称-学校/公司-方向/会议(eg. ACL),进入技术/投稿群
id:DLNLPer,记得备注呦