仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
论文水的部分基本都是在RL前的对比模型的评测上做了点小动作,比如温度设置、输出格式、小样本基准、输出Token长度、之类的。
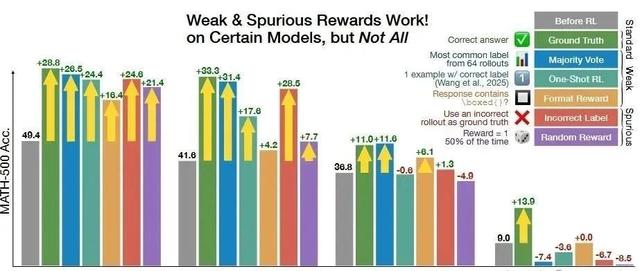
1、SpuriousRewards:RethinkingTrainingSignalsinRLVR
论文主要贡献说是基于RLVR即便使用与正确答案无关、甚至负相关的虚假奖励也能提升模型的数学推理能力。例如,对于Qwen2. 5最高可提升+26. 5%,几乎接近使用真实奖励所获得的28. 8%提升。
问题出在论文中给出的Qwen2. 5的baseline远低于Qwen2.5实际的评分,实际也就提升了5%左右。
2、MaximizingConfidenceAloneImprovesReasoning
论文贡献是提出一种完全无监督的RL方法,无需外部奖励或真实标签,仅使用模型自身预测分布的熵作为内在奖励,当强化模型对于其生成答案的高置信度思维链时,其推理能力也会提升。
问题出在论文给出原模型评分低是因为模型不能遵循他们使用的原始GSM-8K格式输出。但是现在社区已经普遍采用更好的解析方式(如要求输出\boxed{}格式)。模型在这个格式下其实输出良好。而且评分比论文RL后还高,所以RL勒个寂寞?
3、ReinforcementLearningforReasoninginLargeLanguageModelswithOneTrainingExample
论文贡献在将RLVR应用到Qwen2. 5-Math-1. 5B,发现一个样例就可以在MATH-500上从36. 0提升到73.6,在6个常见数学推理基准上的平均准确率从17. 6提高到35.7。
问题出在温度不合理、评测不正确,对比出RL提分更好。
4、LearningtoReasonwithoutExternalRewards
论文提出INTUITOR,用模型自身的自信度评分(self-certaintyscores)替代了GRPO中的外部奖励,实现了完全无监督学习,在数学推理基准上达到了与GRPO相当的性能,并在代码生成等领域的跨域泛化能力上超越GRPO,无需使用真实解答或测试用例。
问题是RL后的模型并未超过官方评估中该模型原本的few-shot准确率,难以判断RL是否真正教授了模型推理能力,可能只是纠正了导致报告中起始模型准确率被低估的问题,比如格式输出问题,因为报告中评估的是zero-shot。
5、Verifree:ReinforcingGeneralReasonerswithoutVerifiers
论文提出了一种无需验证器的方法(VeriFree),绕过答案验证器,转而通过强化学习直接最大化生成参考答案的概率。论文将VeriFree和基于验证器的方法进行了比较,VeriFree在实践中具有明显优势和更少的计算需求,并在多个评测集上打平甚至超过基于验证器的方法。
方法确实超过了官方得分数,但是因为评测使用温度为0,按照Qwen3的官方说法模型能力会退化。这样的比较也会有问题。
6、UnreasonableEffectivenessofEntropyMinimization
论文提出熵最小让模型在最有信心的输出上集中更多概率质量,仅凭这一简单目标、无需任何标注数据,也能显著提升模型在数学、物理与编程任务上的表现。
实际情况还是对比的RL前的模型分数被降了,具体原因可能是温度为0. 1太低之类的问题。
7、CanLargeReasoningModelsSelf-Train?
论文提出一种在线自我训练的强化学习算法,利用模型的自洽性推断正确性信号,无需任何真实标签。算法应用于复杂数学推理任务,性能可以PK金标准答案训练的强化学习方法,无需外部标签的自监督改进可带来显著性能提升。
实际情况RL前的模型分数比论文里的高很多,还是评测参数设置的问题。
学术界水太深了,且行且珍惜。