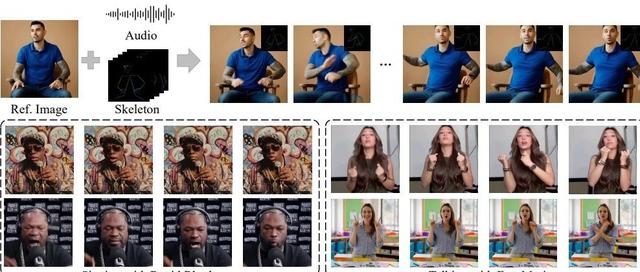
复旦&腾讯优图提出基于扩散的情感说话头像生成方法DICE-Talk,可为说话的肖像生成生动多样的情感。
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
复旦大学和腾讯优图联合提出DICE-Talk,这是一个用于生成具有生动、身份保留的情感表达的谈话头部视频的新框架。可以为会说话的肖像创作出生动多样的情感表达。
论文:https ://arxiv. org/pdf/2504. 18087
代码:https ://github. com/toto222/DICE-Talk
主页:https ://toto222. github.io/DICE-Talk
说话头像生成(THG)的最新进展已通过扩散模型实现了令人印象深刻的唇部同步和视觉质量;然而,现有方法难以在保留说话者身份的同时生成富有情感表达的肖像。我们发现,当前情感说话头像生成存在三个关键限制:对音频固有情感线索的利用不足、情感表征中的身份泄露以及情感相关性的孤立学习。为了应对这些挑战,我们提出了一个名为DICE-Talk的全新框架,其理念是将身份与情感分离,然后将具有相似特征的情感协同起来。首先,我们开发了一个解耦的情感嵌入器,该嵌入器通过跨模态注意力机制对视听情感线索进行联合建模,将情感表示为与身份无关的高斯分布。其次,我们引入了一个相关性增强的情感调节模块,该模块具有可学习的情感库,可以通过矢量量化和基于注意力机制的特征聚合来明确捕捉情感间的关系。第三,我们设计了一个情感识别目标,通过潜在空间分类在扩散过程中增强情感一致性。在MEAD和HDTF数据集上进行的大量实验证明了我们方法的卓越性,在保持口型同步性能的同时,其情绪准确率超越了最先进的方法。定性结果和用户研究进一步证实了我们的方法能够生成具有丰富且相互关联的情绪表情的、可自然适应未知身份的保留身份肖像。
DICE-Talk框架包含三个关键组件:解耦情绪嵌入器、相关性增强的情绪调节器和情绪辨别目标。这些架构元素协同作用,将身份表征与情绪线索分离,同时保留面部表情细节,从而生成具有情感细腻表情的逼真动画肖像。
建议使用具有20GB或更多VRAM的GPU并拥有独立的Python3. 10。
测试的操作系统:Linux
上传图片或拍照
上传或录制音频片段
选择要产生的情绪类型
设定身份保存和情感生成的力量
选择是否裁剪输入图像
感谢你看到这里,也欢迎点击关注下方公众号并添加公众号小助手加入官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、StableDiffusion、Sora等相关技术,欢迎一起交流学习💗~