TMM 2025 | 超越SOTA!AdaMesh用10秒视频生成个性化语音动画,表情生动性提升40%。
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
在虚拟角色与数字人技术中,如何生成兼具真实感与个性化的语音驱动面部动画仍是关键挑战。现有方法往往依赖海量数据或通用模型,难以捕捉用户独特的说话风格(如微表情、头部动态)。为此,由清华大学深圳国际研究生院、商汤科技、香港中文大学等提出的AdaMesh,一种仅需10秒参考视频即可自适应学习个性化说话风格的框架。
表情个性化:引入混合低秩自适应(MoLoRA)模块,通过微调表情适配器高效捕捉面部表情风格,避免传统微调对大量数据的依赖;
姿势个性化:构建离散姿势先验库,结合语义感知姿势风格矩阵,无需微调即可检索并迁移参考视频中的头部姿势特征;
双适配器协同:通过表情与姿势适配器的联合优化,实现语音信号与个性化风格的无缝融合,生成自然、生动的面部动画。
论文:https ://arxiv. org/pdf/2310. 07236
代码:https ://github. com/thuhcsi/AdaMesh
主页:https ://thuhcsi. github.io/AdaMesh
语音驱动的3D面部动画旨在生成与驾驶语音同步的面部运动,近年来得到了广泛的研究。现有的作品大多忽略了生成过程中个人特定的说话风格,包括面部表情和头部姿势风格。一些作品试图通过微调模块来捕捉个性。然而,有限的训练数据导致缺乏生动性。在这项工作中,我们提出了一种新颖的自适应语音驱动面部动画方法AdaMesh,它从大约10秒的参考视频中学习个性化的说话风格并生成生动的面部表情和头部姿势。
具体来说,我们提出混合低秩自适应(MoLoRA)来微调表情适配器,从而有效地捕捉面部表情风格。对于个性化姿势风格,我们通过构建离散姿势先验并使用语义感知姿势风格矩阵检索适当的风格嵌入(无需微调)提出了姿势适配器。大量实验结果表明,我们的方法优于最先进的方法,保留了参考视频中的说话风格,并生成生动的面部动画。
为了实现面部表情的有效适应,对表情适配器进行了预训练,以学习确保唇部同步的一般和与人无关的信息,然后优化MoLoRA参数,使表情适配器具备特定的表情风格。
为了对姿势风格进行建模,提出了一种姿势适配器,将适应性制定为一个简单但有效的检索任务,而不是微调模块。
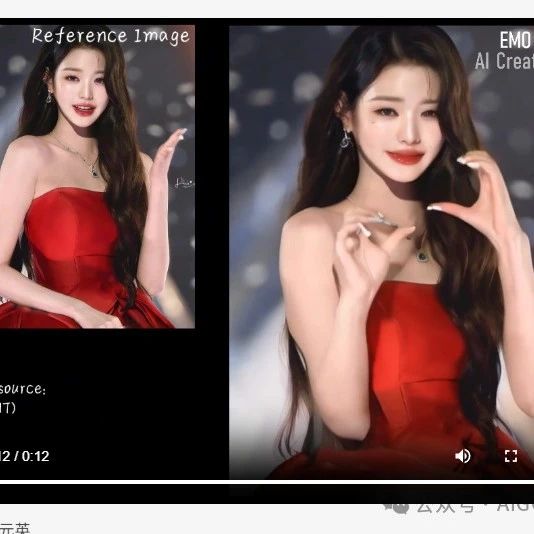
与不同方法的定性比较。(a)展示了奥巴马数据集上说话风格中性的唇部运动。(b)展示了情绪MEAD数据集上个性化面部表情的观察结果。(c)和(d)展示了VoxCeleb2-Test数据集上的头部姿势和相应的关键点轨迹图。第一行显示这些帧正在发音的单词或句子。在肖像逼真说话人脸生成任务上与EMO进行定性比较。英文和中文结果分别给出。
论文提出了一种用于语音驱动的3D人脸动画的AdaMesh方法,旨在从给定的参考视频中捕捉个性化的说话风格,从而生成丰富的人脸表情和多样的头部姿势。我们的核心思想是分别针对人脸表情和头部姿势设计合适的自适应策略。MoLoRA和检索自适应策略符合这两类数据的特点。该方法成功地解决了人脸表情建模的灾难性遗忘和过拟合问题,以及在少量数据自适应的情况下头部姿势建模的平均生成问题。大量的实验结果和方法分析证明,AdaMesh能够实现高质量、高效的风格自适应,并优于其他最先进的方法。
感谢你看到这里,也欢迎点击关注下方公众号并添加公众号小助手加入官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、StableDiffusion、Sora等相关技术,欢迎一起交流学习💗~