3D 生成新 SOTA!SECERN AI 提出 方法 SVAD,单张图像合成超逼真3D Avatar!
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
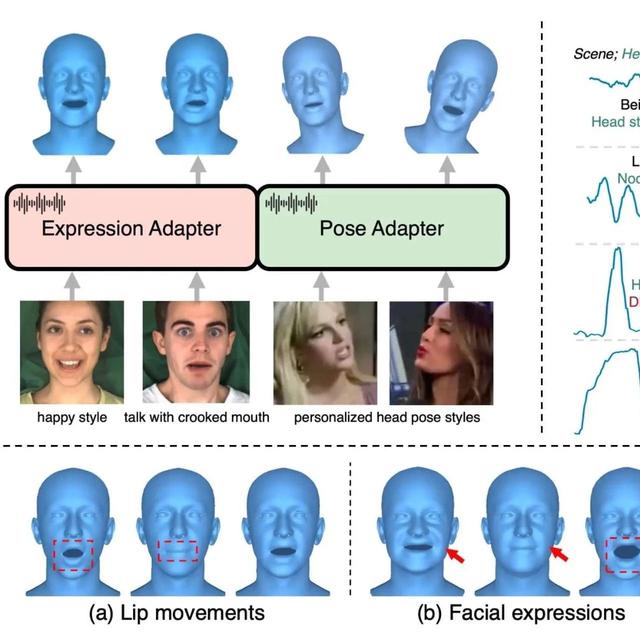
SECERNAI提出的3D生成方法SVAD通过视频扩散生成合成训练数据,利用身份保留和图像恢复模块对其进行增强,并利用这些经过优化的数据来训练3DGS虚拟形象。SVAD在新的姿态和视角下保持身份一致性和精细细节方面优于现有最先进(SOTA)的单张图像方法,同时具备实时渲染能力。
论文:https ://arxiv. org/pdf/2505. 05475
代码:https ://yc4ny. github.io/SVAD
由于从单一视角重建完整3D信息本身就存在困难,因此从单幅图像创建高质量的可动画3D人体形象在计算机视觉领域仍然是一项重大挑战。当前的方法面临一个明显的局限性:3D高斯扩散(3DGS)方法虽然能生成高质量的结果,但需要多个视角或视频序列;而视频扩散模型虽然可以从单幅图像生成动画,但在一致性和身份保留方面却存在困难。
我们提出了SVAD,这是一种新颖的方法,它利用现有技术的互补优势来解决这些局限性。我们的方法通过视频扩散生成合成训练数据,并通过身份保留和图像恢复模块对其进行增强,并利用这些精炼数据来训练3DGS形象。综合评估表明,SVAD在保持身份一致性和精细细节方面优于最先进的(SOTA)单幅图像方法,同时还具备实时渲染功能。通过我们的数据增强流程,我们克服了传统3DGS方法通常需要的对密集单目或多视角训练数据的依赖。
大量的定量和定性比较表明,我们的方法在多个指标上均优于基线模型。通过有效地结合扩散模型的生成能力与3DGS的高质量结果和渲染效率,工作建立了一种基于单幅图像输入生成高保真虚拟形象的新方法。
SVAD的整体流程。扩散模型从单幅输入图像开始,生成基于姿势的动画,并使用身份保存模块和图像恢复模块进行优化。优化后的输出随后用于训练3DGS虚拟人物,从而生成高保真、可动画化的3D虚拟人物,并在不同姿势和视角下保持细节的一致性。
对人物快照数据集和人类数据集扫描渲染图进行定性评估。SVAD仅通过单幅图像输入即可生成高质量、可动画化的3D虚拟形象。
论文介绍了一种新颖的合成数据生成方法SVAD,该方法用于从单幅图像创建高保真、可动画化的3D人体头像。通过结合扩散模型的生成能力和3D高斯分布的渲染效率,SVAD生成的头像能够在不同的姿势和视角下保持一致的身份。通过全面的实验证明了我们的方法达到了SOTA的性能。
局限性和未来工作:该方法面临几个局限性。首先,训练帧的背景分割不准确会产生漂浮伪影。其次,由于视频扩散模型在生成精细合成数据方面的局限性,提出的方法难以处理复杂的服装纹理和宽松的服装。最后,计算需求带来了实际挑战——视频扩散步骤需要大量资源,每个头像生成的完整流程需要5-6小时。未来的工作将侧重于改进对不同服装类型的处理并优化计算性能。
感谢你看到这里,也欢迎点击关注下方公众号并添加公众号小助手加入官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、StableDiffusion、Sora等相关技术,欢迎一起交流学习💗~