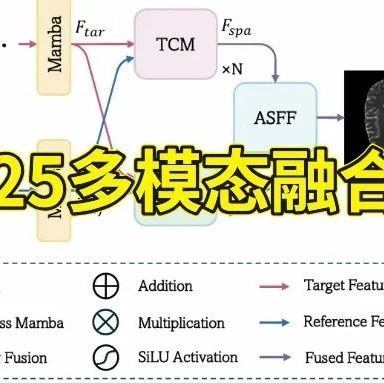
中稿⁺¹ !多模态学习+注意力机制再登顶会!新成果GPU内存消耗减半
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
深度学习找不到创新点?推荐考虑:交叉注意力融合。作为多模态学习和注意力机制这俩大热点的结合,交叉注意力融合凭借动态对齐与高效建模的优势,在众多多模态任务(比如图像-文本匹配)中脱颖而出,发展前景相当可观,成功成为目前发论文的热门选题。
这方向尤其在高效计算、弱监督任务中容易产出创新点,而且根据近年顶会顶刊的收录情况,轻量化、自适应融合、弱监督学习等方向非常值得关注。比如CrossMamba方法,在目标声音提取任务中,参数量减少的同时,既保持了高效计算,又显著提升了性能。
再比如还有ICASSP2025上一种基于交叉注意力融合的方法,GPU内存需求减少了58%…这些成果我挑选了11篇最新高质量论文(有代码),方便有需求的同学了解前沿,做baseline参考,也建议大家结合垂直领域需求创新应用场景。
扫码添加小享,回复“交叉融合”
免费获取全部论文+开源代码
方法:论文提出了一种将视觉输入分块后与音频进行交叉注意力融合的方法,用于音频-视觉情绪识别。具体方法是将计算成本较高的视觉输入分割成多个固定长度的分块,然后在这些分块上执行交叉注意力,而不是直接在原始单模态模型的输出序列长度上进行操作。这种方法在降低计算成本的同时,显著提升了情绪识别的性能。
创新点:
提出了一种新的分块方法,将视觉输入分割成多个小块,用于音频-视觉情绪识别任务。
在分块基础上应用交叉注意力机制,解决了视觉和音频模态在序列长度和计算成本上的差异问题。
实现了在减少计算开销的同时,显著提升情绪识别性能的效果。
方法:论文提出了一种名为CrossMamba的方法,用于目标声音提取任务中的特征融合。它基于Mamba的隐藏注意力机制,将Mamba的计算过程分解为查询、键和值,并利用线索生成查询,利用音频混合信号生成键和值,实现了类似Transformer交叉注意力的特征融合,高效地提取目标声音,同时降低了计算复杂度。
创新点:
提出CrossMamba方法,将Mamba改造成具有交叉注意力功能的模型。
利用线索生成查询(query),音频混合信号生成键(key)和值(value),实现跨序列依赖捕捉。
在AV-SepFormer和Waveformer上验证,证明其性能提升且计算效率更高。
扫码添加小享,回复“交叉融合”
免费获取全部论文+开源代码
方法:论文提出了一种基于交叉注意力融合和物理信息训练的气动系数预测框架。该方法通过分离几何特征和流动条件特征的提取与融合过程,利用交叉注意力机制捕捉形状与流动条件之间的复杂相互作用,并引入物理信息约束作为训练中的引导原则,增强模型在未知条件下的预测能力,有效提升了预测精度和模型的泛化能力。
创新点:
提出了一种基于交叉注意力的气动系数预测模型,能够有效融合几何特征和流动条件特征。
引入物理信息约束作为训练的一部分,增强了模型在未知条件下的预测能力。
通过模块化设计,允许直接利用预训练模型,缓解了气动数据稀缺的问题。
方法:论文提出了一种3D医学图像分割网络DS-UNETR++,通过双分支特征编码机制将图像分为粗粒度和细粒度特征,并利用门控共享加权成对注意力(G-SWPA)模块动态调整空间和通道注意力。在瓶颈阶段,引入门控双尺度交叉注意力模块(G-DSCAM),实现粗粒度和细粒度特征的交叉融合,显著提升了多尺度特征的提取和分割效果。
创新点:
双分支特征编码:将图像分为粗粒度和细粒度特征进行处理,增强对不同尺度特征的捕捉能力。
门控共享加权成对注意力模块:动态调整空间和通道注意力,提升特征提取效率。
门控双尺度交叉注意力模块:融合粗粒度和细粒度特征,提高分割边界准确性。
扫码添加小享,回复“交叉融合”
免费获取全部论文+开源代码