Kimi Researcher 背后的技术思考,关于端到端的RL
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
作者:冯一尘,北京月之暗面科技有限公司
https ://www. zhihu.com/question/1919712376204256921/answer/1920925901035644513
很高兴和大家分享Kimi智能体(Agent)首个产品KimiResearcher背后的一些技术思考。
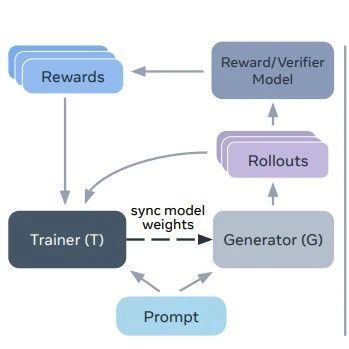
Kimi-Researcher,是一个人类最后一场考试(Humanity’sLastExam)达到SOTA26. 9%、可生成万字追溯报告的模型Agent,也是我们用端到端强化学习(RL)从0到1打磨出来的首个大模型Agent产品。我们构建Kimi-Researcher的核心理念是:我们并非在搭建一个“搜索工具”,而是在训练一个真正会“做研究”的AIAgent。
为了实现这一点,我们选择了一条更难走、但我们坚信是通往更强智能Agent的必经之路:端到端的强化学习(End-to-EndReinforcementLearning)。
其实这个项目从去年上半年立项,到10月份探索版发布,我们内部也经历了不少认知上的转变。随着thinking模型路线逐步清晰,我们意识到有两个关键变量极其重要:
•一是要做“能长思考”的Agent
•二是要用端到端强化学习
为什么要做长思考模型,Flood在这个回答已经解释得很详细,我就重点讲讲我们为什么坚持端到端RL。
目前主要有两种做法:
•Workflow拼装:比如基于OpenAI/Claude去搭建“多Agent+规划器+子任务”,靠手动Prompt和条件规则,把复杂任务拆分成小模块。每换一次底层模型,整个workflow就要大改一遍,灵活性受限。而且基于OpenAI/Claude搭建的Agent在国内也无法开放使用。
•SFT(模仿学习):人工标注完整任务轨迹,Agent模仿这些轨迹,提升Agent整体的能力。但这里面收集数据很耗费人力,难以scale到大量的数据。
这些方案本质都受限于“人能设计/人能标注”的上限,不符合我们相信的scaling
在强化学习的设定下,我们为Agent建立了一个虚拟的环境,让它像一个真正的“科研”新手一样,通过海量的自主探索、试错、并从“做对了”的成功经验中学习,最终“进化”出强大的研究能力。对比传统方法的好处:
RLAgent的行为不是被规则写死的,而是根据当前任务动态生成的。这让它在面对闻所未闻的复杂问题时,有能力探索出创造性的解决方案。我们升级底层模型时,也无需重构整个Agent体系。
当我们发现Agent在某类问题上表现不佳时,我们的解决方案不是去绞尽脑汁地修改Prompt或Workflow,而是将这类问题加入到训练数据中,通过增加“训练题量”和算力,让模型自己学会如何解决。前者的天花板是“人的智慧”,后者的天花板是“数据和算力”——我们坚信后者要高得多。
相比SFT依赖人类标注,RL路线可以让Agent在环境中不断探索,只要我们能准确判断任务是否成功(即提供准确的奖励信号),加大算力去Rollout,就能获得源源不断的、高质量的on-policy训练数据,让模型持续不断地自我迭代和提升。(感兴趣的同学可以去读下TheBitterLesson)
这条路虽然难,但端到端强化学习给我带来了很多惊喜.
在Humanity’sLastExam(人类的最后一场考试)这个榜单上,我们的Agent模型得分从最初的8. 6%跃升至26. 9%,这一巨大增长几乎完全归功于强化学习。这一成绩也走到了世界前沿,相比OpenAIDeepResearch团队在相关工作上从20分左右(o3)提升到26. 6分的成果,进一步证明了强化学习在Agent训练上的巨大价值。
在HLE这个评测集上,我们的pass@4指标达到了40. 17%,这意味着即使面对非常困难的问题,Agent在4次自主尝试内,就有超过四成的概率能成功解决。对于训练而言,只要Agent能探索到正确的路径,我们就有机会把它转化为模型的内在能力。
更有意思的是,我们观察到了很多智能的“涌现”:
•模型在已经很快找到初步答案后,并不会立即停止,而是会主动进行多轮搜索,从不同来源的信息进行交叉验证,以确保结论的准确性。
•我们甚至观察到,模型在遇到一个极度专业的问题、现有信息无法解答时,它会“思考”并产生一个action——“给这篇论文的作者发邮件寻求解答”。(当然,出于安全原因我们拦截了这种action)
这些行为都不是我们预先设计的,而是模型在追求“完成任务”这个最终目标的过程中,自己学会的有效策略。这让我们看到了通往更通用智能的希望。
它能帮你对一个陌生领域快速上手,生成一份带引用的深度报告;能帮你做论文研读和文献综述;甚至能成为你的科研Copilot。我们自己也常用Kimi-Researcher做信息搜集与分析。
我们自己就用Kimi-Researcher去调研“有哪些衡量模型推理能力、且SOTA分数在20分以内的benchmark”,它成功找到了几个我们团队尚未关注到的最新的benchmark,非常有价值。
Kimi除了找到了AGI-2,HLE,OlympiadBench,还找到FrontierMath和6月1日新发布的SealQA。
Prompt:SurveyalladvancedbenchmarksthatallfrontierLLMscoreslowerthan20%,focusontext. examplelikeHLE
Kimiresearcher可以帮你理解复杂知识结构,比如下面这个案例,Kimi依时间线梳理关键事件、制度差异及影响因素,帮助快速把握三大体系的逻辑脉络,为课堂讲解和研究写作提供了结构化材料。
Prompt:分析人类历史上三大货币体系的演变:金本位、布雷顿森林体系、浮动汇率制度
可以快速了解一个陌生领域,比如隐私法,有一个overview:
Kimi在十几分钟内生成了一份信息全面、结构清晰的万字报告,内容涵盖10个国家的关键法规和政策信息、以及核心条款的对比。
关键数据点在可交互报告中一目了然。哪国更宽松、哪国要求更严,不再需要逐段比对文本。
甚至能基于虚拟漫画世界中的比赛数据分析人物角色的技术特点:
Prompt:研究一下灌篮高手的各个球队中主力队员在篮球技术面板的实际能力,给出球探分析报告
Prompt:我最近在考虑入手一个便携榨汁杯,主要是想早上做早餐的时候快速打一杯果汁或代餐奶昔。但我发现现在市面上这种榨汁杯五花八门,价格差异也很大,有的只要五六十元,有的能卖到三四百,甚至看到一些小众品牌比大牌还贵。功能介绍上也都差不多,比如“磁吸充电”“一键启动”“轻音高速电机”等等。请你从一个行业内人士的角度,帮我讲讲:为什么便携榨汁杯在相似功能下价格差这么多?哪些宣传功能是实用的,哪些只是噱头?在一百元左右的预算内,有哪些值得推荐、质量靠谱的款式?我希望你能分析得详细一些,帮我少踩点坑。
总而言之,KimiResearcher不只是一个新功能,更是我们在Agent技术路线上的一次坚定探索和阶段性成果。我们相信,通过强化学习,未来的AIAgent将不再仅仅是“工具”,而是能与人类深度协作的“伙伴”。
进入大模型技术群,备注:进群。