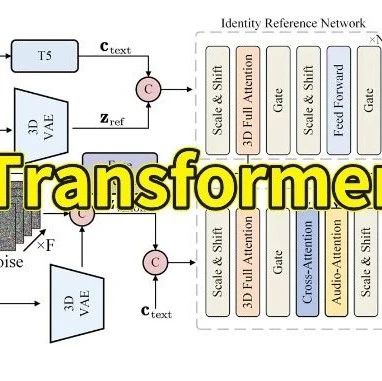
因果机制注入Attention瞬间,高效涨点!3大创新思路抢发顶会!
仅用于站内搜索,没有排版格式,具体信息请跳转上方微信公众号内链接
众所周知,AI模型有个核心痛点——泛化性与可解释性。而因果注意力通过融合因果推理与深度学习,成功解决了这一问题,在OOD场景、多模态任务及高风险决策中相当受欢迎。
当然,这方向在顶会也是“高产领域”。轻量化因果发现(小样本因果图构建)、可解释性增强(注意力权重因果可视化)、领域迁移应用(农业病虫害因果诊断)…都是易出成果的创新路径,ICML、IJCAI等都可一试,感兴趣的同学抓紧冲。
不过总的来说,这方向发论文门槛还是有点高的,建议大家选择以上思路切入的同时,学会站在巨人肩膀上(参考前沿论文、复用成熟工具)进行探索。这里为方便大家找参考,我整理了11篇因果注意力新成果分享,基本都有代码,需要自取~
扫码添加小享,回复“因果注意力”
免费获取全部论文+开源代码
方法:本文提出FarSight解码策略,优化因果掩码减少MLLMs幻觉。通过令牌传播和注意力寄存器结构动态分配注意力,结合位置感知编码方法,增强上下文推理,减少幻觉,同时保持因果解码,防止提前访问未来信息。
创新点:
提出了FarSight,一种插即用的解码策略,通过优化因果掩码来减少多模态大语言模型中的幻觉现象。
设计了注意力寄存器结构,动态分配注意力,捕获被异常令牌分散的注意力,增强上下文推理。
引入了具有逐渐减少掩码率的位置感知编码方法,使模型能够关注更前面的令牌,特别是在视频序列任务中。
方法:论文反思视觉-语言模型因果注意力,提出未来感知机制。实验发现传统掩码限制视觉令牌,故提新策略允许预填充访问未来令牌。还设计轻量级注意力机制,池化合并语义,提升效率。多任务实验证明方法有效,性能显著提升。
创新点:
提出了三种未来感知因果掩码策略,允许视觉令牌访问未来的视觉或文本令牌,增强跨令牌依赖。
发现传统的因果掩码对视觉令牌过于严格,限制了模型利用未来上下文的能力。
提出了一种轻量级的注意力机制,通过池化将未来的语义注意力合并到过去的表示中,提高了计算效率。
扫码添加小享,回复“因果注意力”
免费获取全部论文+开源代码
方法:论文提出了一种名为AKI的多模态大语言模型,通过引入模态互注意力机制,允许图像令牌在训练过程中关注文本令牌,从而解决了传统模型中图像和文本信息错位的问题。这种方法在多个基准测试中显著提升了性能,且无需额外参数或增加训练时间。
创新点:
提出了一种新的模态互注意力(MMA)机制,允许图像令牌在监督微调阶段关注文本令牌,打破了传统因果注意力机制的限制。
这种设计无需引入额外参数或增加训练时间,能够无缝集成到现有的多模态大语言模型(MLLM)训练框架中。
在12个多模态理解基准测试中,AKI模型显著提升了性能,平均性能比现有最佳基线提高了7. 2%。
方法:论文提出了一种名为“LearningtoFocus”(LeaF)的框架,通过识别和修剪训练数据中的混淆令牌,帮助大型语言模型(LLMs)在推理时更专注于关键信息,从而提高模型在数学推理和代码生成任务中的表现。
创新点:
提出两阶段方法,结合因果分析与梯度修剪,识别并消除混淆令牌,增强学生模型对可靠因果依赖的捕捉。
在数学与代码基准测试中,显著提高了准确性和鲁棒性,验证了关注关键信息对推理性能的重要性。
通过注意力可视化展示,LeaF使模型在推理时避免混淆令牌,聚焦于关键信息,增强了可解释性。
扫码添加小享,回复“因果注意力”
免费获取全部论文+开源代码